集成学习之前向分步算法与梯度提升决策树GBDT
本文共 1277 字,大约阅读时间需要 4 分钟。
集成学习之前向分步算法与梯度提升决策树GBDT
前向分步算法
引用源github:https://github.com/pandali1/DataScience/tree/main/%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0/ch3
加法模型
Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即: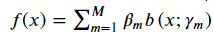
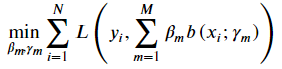
向前分步算法

前向分步算法与Adaboost的关系
Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。
梯度提升决策树(GBDT)
基于残差学习的提升树算法
Adaboost算法,并没有涉及回归的例子。上一节提到了一个加法模型+前向分步算法的框架,可以用加法模型+前向分步算法的框架实现回归问题。
使用加法模型+前向分步算法的框架解决问题之前,首先需要确定框架内使用的基函数,这里使用决策树分类器。回归树等树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。基函数确定了以后,我们需要确定每次提升的标准。 Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,回归问题没有分类错误率也就没办法在这里使用了,因此我们模仿分类错误率,用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法: 能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。该算法还有提升的空间
能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。该算法还有提升的空间 梯度提升决策树算法(GBDT)
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,对比以下损失函数:

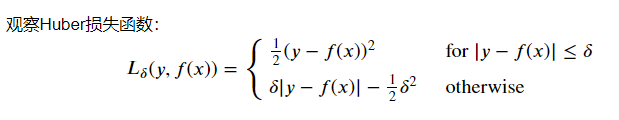 针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。 梯度提升算法:
针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。 梯度提升算法: 
代码实践(待补充)
转载地址:http://ragwi.baihongyu.com/
你可能感兴趣的文章
linux获得系统编码
查看>>
Ubuntu安装glib
查看>>
MySQL存储过程,生成大量数据
查看>>
查询字段值出现多次的字段值
查看>>
SQL Server表存在则进行查重 SQL语句
查看>>
redhat 9 下sqlite 3的安装及编程
查看>>
两个同步表的字段复制.Oracle.
查看>>
windows MySQL 报“Got a packet bigger than 'max_allowed_packet' bytes”错误,解决过程.
查看>>
MFC ADO连MySQL,使用数据源.
查看>>
在Redhat9下静态编译glib库.
查看>>
在ubuntu12下静态编译freetype库.
查看>>
CImg库编译使用.
查看>>
SQL Server循环执行动态SQL语句.
查看>>
windows MySQL报"2006 - MySQL server has gone away"错误,解决过程.
查看>>
ubuntu10.4网卡名由eth0改为eth4,导致获得不了IP地址.解决方法.
查看>>
CheckPoint关键词做字段名使用.
查看>>
Qt QSplitte分割器使用(用户手动改变窗口大小)
查看>>
根据高度图计算体积等。
查看>>
Qt动态加载动态库
查看>>
使用VS2015创建纯C动态库。
查看>>